
SEO-Optimierung der Facettennavigation für Online-Shops
Facettennavigation, also die Möglichkeit in Online-Shops nach Eigenschaften wie Preis, Farbe oder Marke zu filtern, verbessert die Nutzererfahrung – birgt aber erhebliche SEO-Risiken. Unsachgemäß umgesetzt, entstehen massenhaft URLs mit ähnlichem Inhalt, die Suchmaschinen-Crawler in eine Endlosschleife schicken können. Die Folgen: Verschwendung des Crawl-Budgets, doppelte Inhalte, verwässerte interne Verlinkung und technische Komplexität bei der URL-Verwaltung. In diesem Artikel analysieren wir die größten SEO-Probleme der Facettennavigation und zeigen strategische Lösungen auf – inklusive moderner Techniken wie robots.txt, Canonical Tags, Noindex, Google Search Console-Parametersteuerung sowie AJAX/JavaScript-Lösungen. Code-Beispiele (fehlerhaft vs. optimiert) veranschaulichen typische Fehler und Best Practices. Außerdem betrachten wir Shop-spezifische Hinweise (für Magento, Shopify, WooCommerce), um praxisnahe Empfehlungen für Shops mit umfangreichen Filteroptionen zu geben.
Typische SEO-Probleme der Facettennavigation
Crawling- & Indexierungsprobleme (Crawl-Budget)
Suchmaschinen behandeln jede einzigartige URL separat. Bei facettierten Filtern führt dies häufig zu Index Bloat – einer Aufblähung des Index mit unzähligen Varianten, die keinen eigenen Suchwert haben. Google-Bots versuchen erst durch Crawling herauszufinden, ob eine URL nützlich ist; Facetten mit URL-Parametern erzeugen jedoch praktisch unendliche URL-Räume, die den Crawler in Beschlag nehmen. Das Ergebnis ist Overcrawling: Crawler verschwenden Zeit auf unnötigen Filterseiten, während wichtige Seiten zu kurz kommen. Google bestätigt, dass solche duplizierten Facetten-URLs das Crawl-Budget verschwenden und die Server unnötig belasten. Sichtbar wird dieses Problem z.B. durch eine Diskrepanz zwischen tatsächlicher Seitenanzahl und den in der Suche gelisteten Seiten (Anzeichen für Index-Bloat). Im Worst Case verzögert dies die Indexierung neuer Inhalte erheblich.
Eine eindrucksvolle Fallstudie von Skroutz & Botify zeigt, wie drastisch sich unkontrollierte Facettennavigation auf die Indexierung auswirken kann. In einem untersuchten Online-Shop machten über 70 % der indexierten Seiten nutzlose Facetten-URLs aus – also Seiten, die kaum oder keinen eigenständigen Mehrwert für Suchmaschinen oder Nutzer bieten. Das folgende Diagramm verdeutlicht, wie sich der Index einer E-Commerce-Seite ohne gezielte Steuerung zusammensetzen kann:
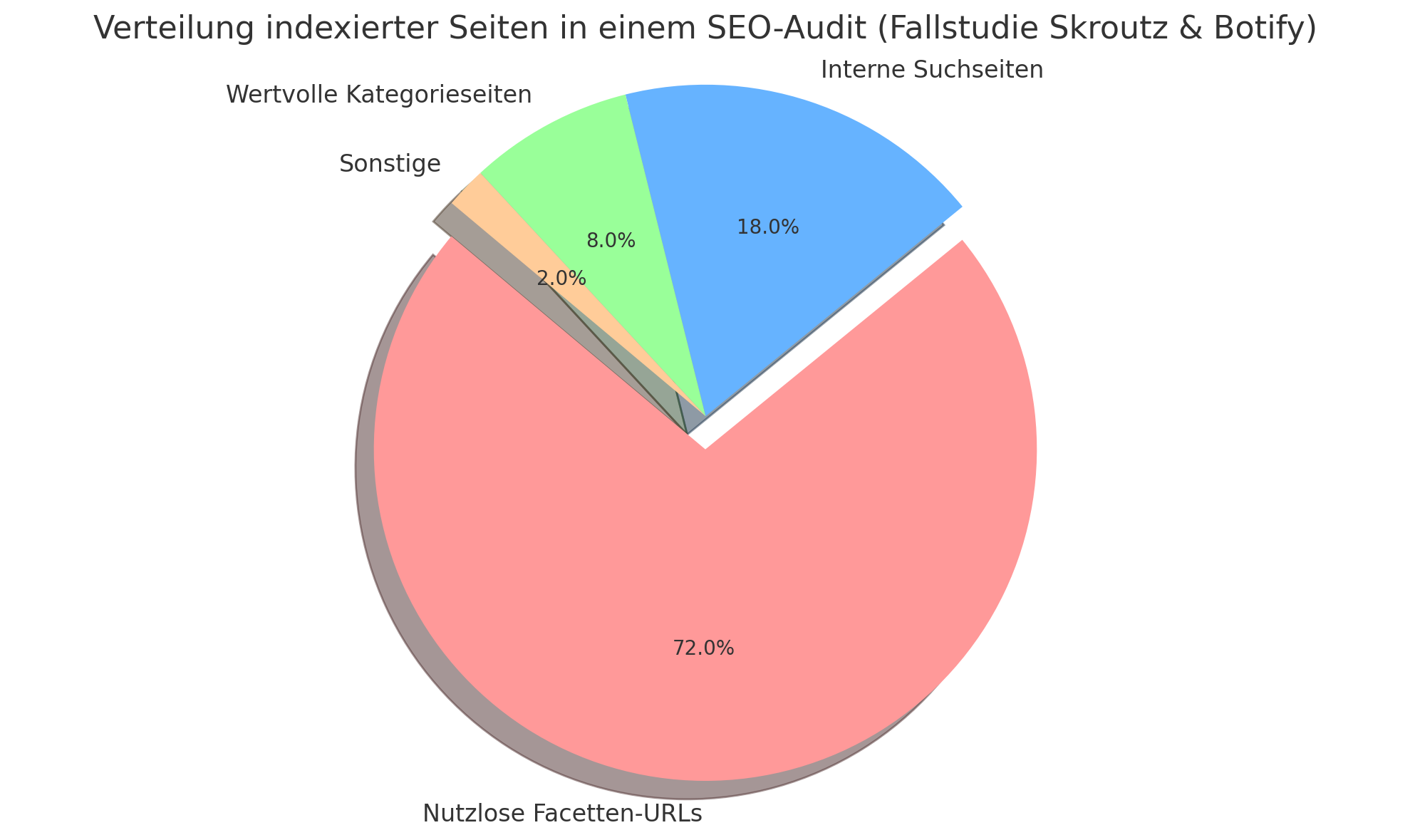
Hinweis: Dieses Verhältnis ist keine Ausnahme – viele große Shops kämpfen mit vergleichbaren Problemen durch nicht kontrollierte Facettennavigation.
Duplicate Content durch Filtervarianten
Facettennavigation erzeugt oft doppelten Inhalt, da viele Filterkombinationen letztlich ähnliche Produktlisten anzeigen. Beispielsweise kann dasselbe Sortiment an Schuhen unter /schuhe?farbe=rot und /schuhe?farbe=rot&größe=42 erreichbar sein. Suchmaschinen werten solche Seiten als eigenständige URLs – obwohl der Kerninhalt (Produktbeschreibung, Kategorien-Text) identisch ist. Offiziell führt Duplicate Content zwar nicht zu manuellen Abstrafungen, verwässert aber die Relevanz: Rankingsignale und Backlinks verteilen sich auf mehrere URLs statt auf eine konzentrierte. Zudem droht Keyword-Kannibalisierung, wenn mehrere Varianten um dieselben Suchbegriffe konkurrieren. Besonders Filterseiten, die sehr ähnliche oder keine eigenständigen Inhalte haben (z. B. lediglich sortiert nach Preis), können als wertarm eingestuft werden und die gesamte Domainqualität beeinträchtigen. Das Phänomen „Index Bloat“ überschneidet sich hier: Viele duplizierte Seiten ohne eigenen Mehrwert erschweren Google ein klares Bild der Website-Struktur.
Interne Verlinkung & PageRank-Verlust
Ein oft übersehener Aspekt: Interne Links in der Facettennavigation. Filtermenüs erzeugen zahlreiche Links (etwa zu jeder Farbkombination), die auf jeder Kategorieseite präsent sein können. Dadurch verteilt sich der interne PageRank auf unzählige Filter-URLs, anstatt die wichtigsten Seiten zu stärken. Diese Verdünnung der Linkpower schwächt u.U. die Rankings der Hauptkategorien und Produkte. Noch problematischer: Wenn geblockte Facettenseiten (z. B. via robots.txt) weiterhin intern verlinkt sind, crawlt Google sie trotz Blockade über eingehende Links – das Crawl-Budget wird trotzdem verbraucht und der Index mit „toten Seiten“ gefüllt. Falsch gesetzte interne Links (etwa facettierte URLs ohne Nutzen) stören also die SEO-Architektur und lenken sowohl Crawler als auch Nutzer vom Wesentlichen ab.
Technische Herausforderungen (URL-Parameter, Filter & Co.)
Die technische Umsetzung von Facettennavigation stellt SEO vor knifflige Aufgaben. Klassisch werden Filter über URL-Parameter realisiert (z. B. ?farbe=rot&marke=adidas); ohne besondere Vorkehrungen erzeugt jede Kombination eine einzigartige URL. Auch Sortierungen oder Paginierungen erzeugen weitere Varianten. Herausforderungen hierbei sind:
- Parameter-Steuerung: Das frühere URL-Parameter-Tool in der Google Search Console erlaubte es, Crawlern das Verhalten bei bestimmten Parametern vorzugeben – z. B.
sortieren=nicht indexieren. Google hat dieses Tool im April 2022 abgeschafft, weil es kaum genutzt wurde. Seither versucht die Suchmaschine, Parameter-Effekte automatisch zu erkennen. Für Website-Betreiber bedeutet das aber weniger direkte Kontrolle. - URL-Konsistenz: Unterschiedliche Reihenfolgen oder Schreibweisen von Parametern können jeweils neue URLs bedeuten. Wenn z. B.
/shirts?stil=casual&farbe=blauund/shirts?farbe=blau&stil=casualexistieren, vervielfacht sich die URL-Anzahl unnötig. Ohne feste URL-Struktur erzeugen unterschiedliche Filterreihenfolgen schnell eine Explosion an Kombinationen. - Technische Limits: Manche Shopsysteme erstellen für jede Filterausprägung statische Pfade (z. B.
/hosen/blau/), andere nutzen Hash-Fragmente (#filter=blau) oder rein JavaScript-gesteuerte Filter. Jede Methode hat Vor- und Nachteile: Hash-Fragmente ignoriert Google zwar beim Crawlen (somit keine Indexierung), sind aber nicht optimal für Barrierefreiheit und Sharing (wie Experten anmerken). Rein clientseitige Filter (AJAX) erzeugen keine URLs, können aber ohne zusätzliche Maßnahmen auch keine gezielten SEO-Landingpages bereitstellen. Die Balance zwischen SEO-Sichtbarkeit und technischer Sauberkeit ist hier schwierig.
Strategien zur SEO-Optimierung der Facettennavigation
Angesichts dieser Probleme ist eine strategische Herangehensweise nötig, um die Vorteile der Facettensuche zu nutzen, ohne die SEO-Performance zu gefährden. Im Kern geht es um Selektion und Kontrolle: Welche Facetten sollen suchmaschinenrelevant sein – und wie blockt man den Rest effizient? Folgende Leitfragen und Lösungen helfen bei der Optimierung:
Wann sollte eine Facettenseite indexiert werden (und wann nicht)?
Nicht jede Filterkombination verdient einen Platz im Google-Index. Als Faustregel gilt: Indexierbar sind Facettenseiten nur, wenn sie eigenständig Suchwert bieten. Das ist z. B. der Fall, wenn für die Facetten-Kombination relevantes Suchvolumen existiert oder Nutzer gezielt danach suchen (Stichwort Long-Tail-Keywords). Ein Online-Shop für Kleidung könnte etwa feststellen, dass viele Nutzer nach „Adidas Herren T-Shirt grau“ suchen – es lohnt sich, eine entsprechende gefilterte Seite indexierbar zu machen. Große Shops wie Zalando behandeln bestimmte Facetten deshalb wie eigene Landingpages (z. B. /t-shirts/adidas_grau/ für graue Adidas-T-Shirts), mit sprechenden URLs, eigenen H1-Titeln und Canonical Tags. Solche Seiten können in Google ranken und zusätzlichen Traffic bringen.
Andererseits gibt es unzählige Filterkombinationen ohne Suchnachfrage. Ein Nutzer mag fünf Filter gleichzeitig setzen, um das perfekte Produkt zu finden – aber kein Mensch sucht exakt nach dieser Kombination im Web. Diese Seiten sollten nicht indexiert werden. Denn sie würden nur „Indexbloat“ erzeugen und potentiell als Thin Content gelten (z. B. wenn kaum Produkte angezeigt werden). Studien zeigen, dass Millionen solcher Seiten die Domainqualität sogar negativ beeinflussen können. Die Kunst besteht also darin, wertvolle Facetten herauszufiltern:
- Analyse von Suchvolumen: Prüfen Sie, welche Filterbegriffe oder -kombinationen nennenswert gesucht werden (z. B. via Keyword-Tools). Beliebte Facetten können als eigenständige Seiten aufbereitet werden (mit eigenem SEO-Text, Meta-Description etc.). Wenig gefragte Filter können dagegen verborgen oder blockiert werden.
- Kategorisierung nach Ebene: Oft sind einzelne Filter (nur Farbe oder nur Marke) suchrelevant, während tiefe Kombinationen (Marke + Farbe + Größe + Feature) zu spezifisch sind. Man kann entscheiden, z. B. nur Einzelfilter indexierbar zu halten, aber Kombinationsfilter auf Noindex zu setzen.
- Dynamische vs. Statische Facettenseiten: Für wichtige Filter können statische, SEO-freundliche URLs angelegt werden (z. B. eigene Kategorie-Unterseiten für „Damen > Schuhe > Rot“). Diese lassen sich in die interne Verlinkung einbinden und mit unique Content versehen. Unwichtige Filter bleiben rein dynamisch (nur per AJAX, ohne eigene URL) oder erhalten einen
noindex.
Interne Verlinkung sinnvoll nutzen
Die interne Linkstruktur eines Shops sollte gewichtige Seiten priorisieren – also Kategorien, Topseller, relevante Landingpages. Facettenlinks im Filtermenü sind oft automatisch auf jeder Seite präsent und können schnell zur Linkfalle werden. Hier einige Strategien:
- Nicht indexierbare Facetten nicht verlinken: Filter, die per
robots.txtblockiert oder vianoindexausgesperrt werden, sollten idealerweise gar nicht als crawlbare Links im HTML stehen. Andernfalls finden Crawler sie dennoch und versuchen, sie aufzurufen. Lösungen sind etwa, solche Links mitrel="nofollow"zu versehen oder rein per JavaScript-Klick (ohne<a>-Link) zu implementieren. So verschwenden diese URLs kein Crawl-Budget und tauchen nicht in der internen Linkgrafik auf. - Wichtige Facettenseiten gezielt verlinken: Falls bestimmte Filterseiten indexierbar sein sollen, sollten sie auch aktiv unterstützt werden. Zum Beispiel kann eine kategorienahe Facette (z. B. „Herren > Schuhe > Schwarz“) von der Hauptkategorieseite per SEO-Textlink erreichbar sein. Kontextsensitive Verlinkung (etwa im Fließtext „Entdecken Sie auch unsere Auswahl an < href="/herren-schuhe/schwarz/">schwarzen Herrenschuhen“) verleiht diesen Seiten zusätzliches Gewicht.
- Breadcrumbs & Navigation prüfen: Bei manchen Shopsystemen erscheinen angewendete Filter als Teil der Breadcrumb-Navigation (z. B. Home > Schuhe > Herren >Filter: Schwarz).) – sicherzustellen ist, dass dabei keine ungewollten indexierbaren URLs generiert werden. Ggf. sollten Breadcrumb-Links zu gefilterten Zuständen vermieden oder auf kanonische URLs verweisen.
Durch kluge interne Verlinkung hält man den Link Juice bei den wichtigen Seiten und verhindert die von facettierten Links verursachte PageRank-Verdünnung.
Lösungen für Shops mit umfangreicher Filter-Navigation
Shops mit hunderten Filtern (z. B. große Marktplätze oder Sortimente mit vielen Attributen) brauchen klare Richtlinien, um der Filter-Flut Herr zu werden:
- Robuste Informationsarchitektur: Definieren Sie eine feste Hierarchie oder Logik, welche Filter kombiniert werden dürfen und wie URLs aufgebaut sind. Konsistente URL-Strukturen sind entscheidend: Legen Sie z. B. fest, dass stets die Reihenfolge Kategorie > Marke > Farbe genutzt wird. So vermeiden Sie doppelte URLs mit vertauschter Reihenfolge.
- Begrenzung der Kombinationsvielfalt: Überlegen Sie, gewisse Filter nur alleinstehend zuzulassen. Beispiel: Es könnten zwar Farbe oder Größe gefiltert werden, aber nicht beides gleichzeitig, wenn daraus kein Mehrwert entsteht. Jede zusätzliche Dimension erhöht die URL-Multiplikation exponentiell.
- AJAX & Load-More statt Paginated URLs: Wenn sehr viele Produkte zu laden sind, nutzen einige Shops „Load more“-Buttons oder unendliches Scrollen statt klassischer Pagination (z. B. ?page=2 etc.). Dies kann die Anzahl indexierbarer Seiten reduzieren – sofern keine HTML-Links für Folgeseiten generiert werden. Aber Vorsicht: Stellt sicher, dass Google zumindest den ersten Teil des Produktindex erfassen kann oder eine alternative Paginierung per Link vorhanden ist, um Linkjuice zu verteilen.
- Sonderfall Suchseiten: Oft bieten Shops neben Filtern auch eine Suche an. Interne Suchergebnisse sollten grundsätzlich mit
noindexversehen werden, um Duplicate Content zu vermeiden. Gleiches gilt für sehr fein granulare Filterkombinationen. - Monitoring & Feinsteuerung: Bei umfangreichen Facetten lohnt es sich, die Indexierungsstatistiken regelmäßig zu überwachen – etwa in der Google Search Console. Ein plötzlicher Anstieg an indexierten Filterseiten (z. B. „Gültig, aber nicht in Sitemap eingereicht“) kann auf Probleme hinweisen, die durch Nachjustieren von Disallow-Regeln oder Noindex-Tags behoben werden müssen.